Star schema in dimensional modelling
If you’re diving into the world of dimensional data modelling, you’ve likely come across the term “star schema.” In this guide, we’ll cover what a star schema is, why it’s important, and in what scenario its use is best-suited.
Whether you’re a data engineer, analyst, or just curious about data architecture, you’ll find practical insights and examples to help you grasp this foundational concept in data management.
What is a star schema?
ℹ️ A star schema is a dimensional modelling technique used to organise data in a database or warehouse, especially for analytics and reporting. It’s called a “star” because the structure resembles a star: in the middle, there is a central table (the fact table) surrounded by related tables (the dimension tables).
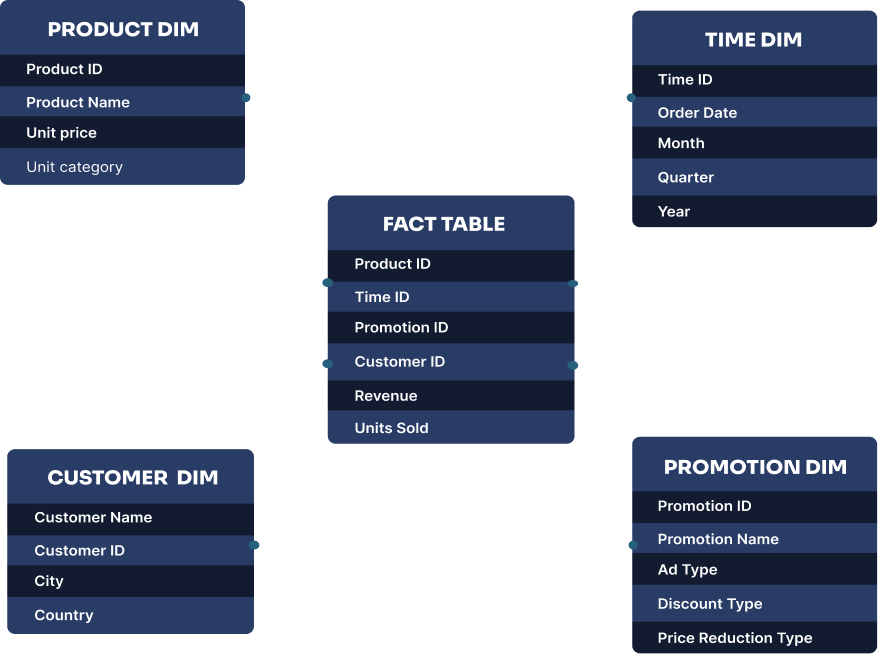
A fact table is always at the core of the star. It stores measurable data, like sales amounts, quantities, or performance metrics. Each row in the fact table represents a specific event or transaction.
The fact table might store sales transactions with columns like:
| product_id | time_id | promotion_id | customer_id | revenue | units_sold |
|---|---|---|---|---|---|
| 101 | 202303 | 1 | 1001 | 500.00 | 2 |
| 102 | 202303 | 2 | 1002 | 300.00 | 1 |
| 103 | 202304 | 3 | 1003 | 700.00 | 3 |
The dimension tables are the “spokes” of the star. They provide descriptive information about the facts, like dates, products, customers, or locations. In a star schema, dimension tables are typically smaller and contain more readable and human-friendly names for the data.
The dimension tables might include:
| product_id | name | category |
|---|---|---|
| 101 | Laptop | Electronics |
| 102 | Smartphone | Electronics |
| 103 | Tablet | Electronics |
| customer_id | name | region |
|---|---|---|
| 1001 | Alice | North |
| 1002 | Bob | South |
| 1003 | Charlie | East |
| time_id | day | month | year |
|---|---|---|---|
| 202303 | 15 | March | 2023 |
| 202304 | 10 | April | 2023 |
Since the dimension tables are joined with the fact table, the structure allows you to easily query the data to answer questions like: “What was the total revenue in March 2023?” or “Which products were most popular in the North region?”.
Why use a star schema?
Star schemas might take some effort to set up, but their structured design is key to building solid data architectures. They are simple to understand and use, even for non-technical users. Star schemas are optimised for fast queries, which is perfect for creating reports and dashboards. Since they require fewer joins compared to more complex schemas, they perform well with large datasets and are ideal for read-heavy tasks like analytics.
What is the difference between a star schema and a snowflake schema?
In a star schema, dimension tables are designed to be straightforward and easy to use. They are denormalised, which means they might store some repeated information to make queries simpler and faster. This setup is great for analytics and reporting because all the descriptive details you need are right there in the dimension tables, which means you’ll less likely have to do complex joins.
A snowflake schema, on the other hand, takes a slightly different approach. It normalises the dimension tables, breaking them into smaller, related tables to avoid redundancy. For example, instead of including the category name directly in the Products table, it might be stored in a separate Categories table. While this saves storage space and ensures consistency, it can make queries a bit more complex since you’ll need to join multiple tables to get the same information. Snowflake schemas are a bit slower for read-heavy tasks like reporting, but they are best suited when storage efficiency and data consistency are top priorities.
Here is a quick overview of the key differences between a star and snowflake schema:
| Feature | Star Schema | Snowflake Schema |
|---|---|---|
| Structure | Denormalised | Normalised |
| Query Complexity | Simple | More complex |
| Storage Efficiency | Less efficient (redundant data) | More efficient (less redundancy) |
| Performance | Optimised for fast queries | May require more joins, slower |
| Use Case | Optimised for reporting and analytics | Optimised for storage and consistency |
When to use a star schema?
A star schema is best-suited to organisations prioritising query performance and simplicity. It is ideal for scenarios where the primary goal is to enable fast, straightforward reporting and analytics. For example, generating dashboards, summarising sales performance, or tracking KPIs.
A star schema is also a solid choice for teams with non-technical users who need to interact with the data, as the schema’s intuitive design makes it easier to understand and use without requiring advanced SQL knowledge.
It is less suitable, however, for use cases where storage efficiency or strict data consistency is a higher priority, as the denormalisation can lead to some redundancy in the data.
Star schemas help build efficient and user-friendly data systems. They make it easier to organise and query your data, especially when speed and simplicity are key. By understanding the strength of star schemas, you’ll be better equipped to design data models that support insightful analytics and decision-making.
How many dimensions can a star schema have?
+What is the difference between a star schema and a relational database?
+About the author

See Bragi in action
Explore how Bragi can optimise your data architecture
Speak directly to Bragi’s co-founders, not a sales agent, and explore how Bragi can automate your data processes and transform your data workflows.